Caching v2
Beta
This Kubeflow component has beta status. See the Kubeflow versioning policies. The Kubeflow team is interested in your feedback about the usability of the feature.Starting from Kubeflow Pipelines SDK v2 and Kubeflow Pipelines 1.7.0, Kubeflow Pipelines supports step caching capabilities in both standalone deployment and AI Platform Pipelines.
Before you start
This guide tells you the basic concepts of Kubeflow Pipelines caching and how to use it. This guide assumes that you already have Kubeflow Pipelines installed or want to use standalone or AI Platform Pipelines options in the Kubeflow Pipelines deployment guide to deploy Kubeflow Pipelines.
What is step caching?
Kubeflow Pipelines caching provides step-level output caching, a process that helps to reduce costs by skipping computations that were completed in a previous pipeline run.
Caching is enabled by default for all tasks of pipelines built with Kubeflow Pipelines SDK v2 using kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE mode.
When Kubeflow Pipeline runs a pipeline, it checks to see whether
an execution exists in Kubeflow Pipeline with the interface of each pipeline task.
The task’s interface is defined as the combination of the pipeline task specification (base image, command, args), the pipeline task’s inputs (the name and id of artifacts, the name and value of parameters),
and the pipeline task’s outputs specification (artifacts and parameters).
Note: If the producer task which generates an artifact is not cached, then the producer task will generate a new artifact with different ID, and downstream task which uses the artifact generated by the producer task won’t hit cache.
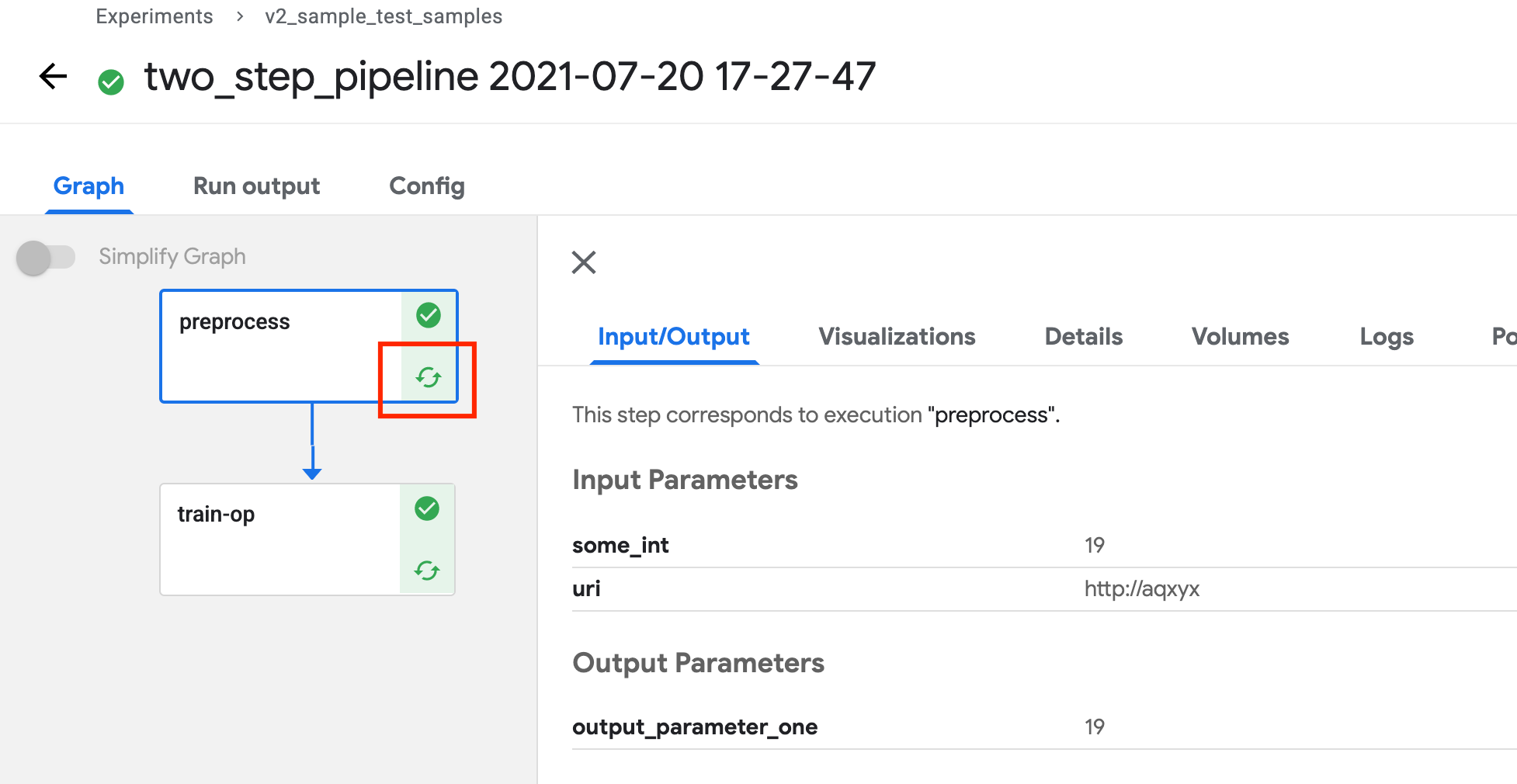
If there is a matching execution in Kubeflow Pipelines, the outputs of that execution are used, and the task is skipped. An example of cache being hit:
Disabling/enabling caching
Cache is enabled by default with Kubeflow Pipelines SDK v2 using kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE mode.
You can turn off execution caching for pipeline runs that are created using Python. When you run a pipeline using create_run_from_pipeline_func or create_run_from_pipeline_package or run_pipeline you can use the enable_caching argument to specify that this pipeline run does not use caching.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.