Architecture
This guide introduces Kubeflow as a platform for developing and deploying a machine learning (ML) system.
Kubeflow is a platform for data scientists who want to build and experiment with ML pipelines. Kubeflow is also for ML engineers and operational teams who want to deploy ML systems to various environments for development, testing, and production-level serving.
Conceptual overview
Kubeflow is the ML toolkit for Kubernetes.
The following diagram shows Kubeflow as a platform for arranging the components of your ML system on top of Kubernetes:

Kubeflow builds on Kubernetes as a system for deploying, scaling, and managing complex systems.
Using the Kubeflow configuration interfaces (see below) you can specify the ML tools required for your workflow. Then you can deploy the workflow to various clouds, local, and on-premises platforms for experimentation and for production use.
Introducing the ML workflow
When you develop and deploy an ML system, the ML workflow typically consists of several stages. Developing an ML system is an iterative process. You need to evaluate the output of various stages of the ML workflow, and apply changes to the model and parameters when necessary to ensure the model keeps producing the results you need.
For the sake of simplicity, the following diagram shows the workflow stages in sequence. The arrow at the end of the workflow points back into the flow to indicate the iterative nature of the process:

Looking at the stages in more detail:
-
In the experimental phase, you develop your model based on initial assumptions, and test and update the model iteratively to produce the results you’re looking for:
- Identify the problem you want the ML system to solve.
- Collect and analyze the data you need to train your ML model.
- Choose an ML framework and algorithm, and code the initial version of your model.
- Experiment with the data and with training your model.
- Tune the model hyperparameters to ensure the most efficient processing and the most accurate results possible.
-
In the production phase, you deploy a system that performs the following processes:
- Transform the data into the format that your training system needs. To ensure that your model behaves consistently during training and prediction, the transformation process must be the same in the experimental and production phases.
- Train the ML model.
- Serve the model for online prediction or for running in batch mode.
- Monitor the model’s performance, and feed the results into your processes for tuning or retraining the model.
Kubeflow components in the ML workflow
The next diagram adds Kubeflow to the workflow, showing which Kubeflow components are useful at each stage:

To learn more, read the following guides to the Kubeflow components:
-
Kubeflow includes services for spawning and managing Jupyter notebooks. Use notebooks for interactive data science and experimenting with ML workflows.
-
Kubeflow Pipelines is a platform for building, deploying, and managing multi-step ML workflows based on Docker containers.
-
Kubeflow offers several components that you can use to build your ML training, hyperparameter tuning, and serving workloads across multiple platforms.
Example of a specific ML workflow
The following diagram shows a simple example of a specific ML workflow that you can use to train and serve a model trained on the MNIST dataset:

For details of the workflow and to run the system yourself, see the end-to-end tutorial for Kubeflow on GCP.
Kubeflow interfaces
This section introduces the interfaces that you can use to interact with Kubeflow and to build and run your ML workflows on Kubeflow.
Kubeflow user interface (UI)
The Kubeflow UI looks like this:
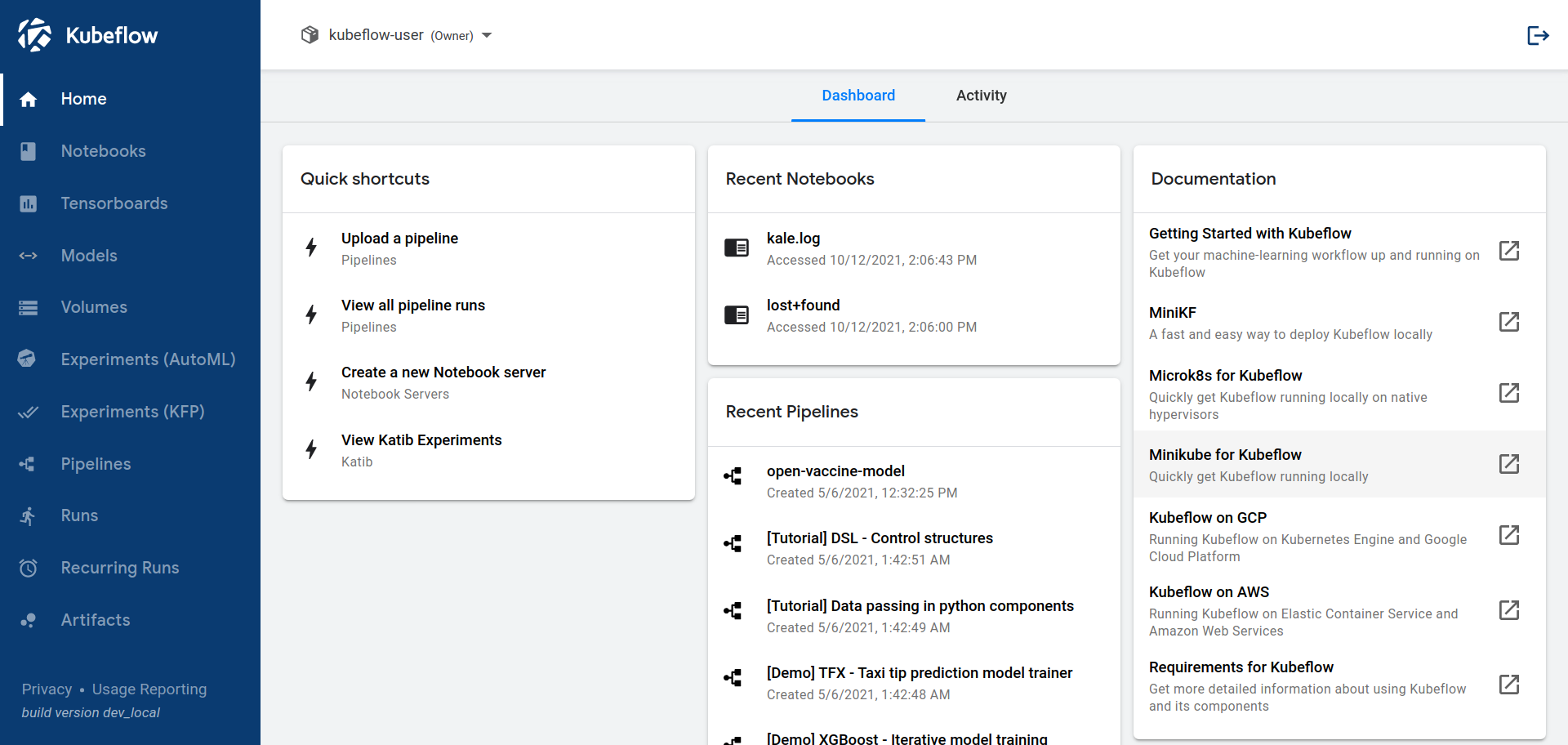
The UI offers a central dashboard that you can use to access the components of your Kubeflow deployment. Read how to access the central dashboard.
Kubeflow APIs and SDKs
Various components of Kubeflow offer APIs and Python SDKs. See the following sets of reference documentation:
- Pipelines reference docs for the Kubeflow Pipelines API and SDK, including the Kubeflow Pipelines domain-specific language (DSL).
- Fairing reference docs for the Kubeflow Fairing SDK.
Next steps
- Follow Installing Kubeflow to set up your environment and install Kubeflow.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.